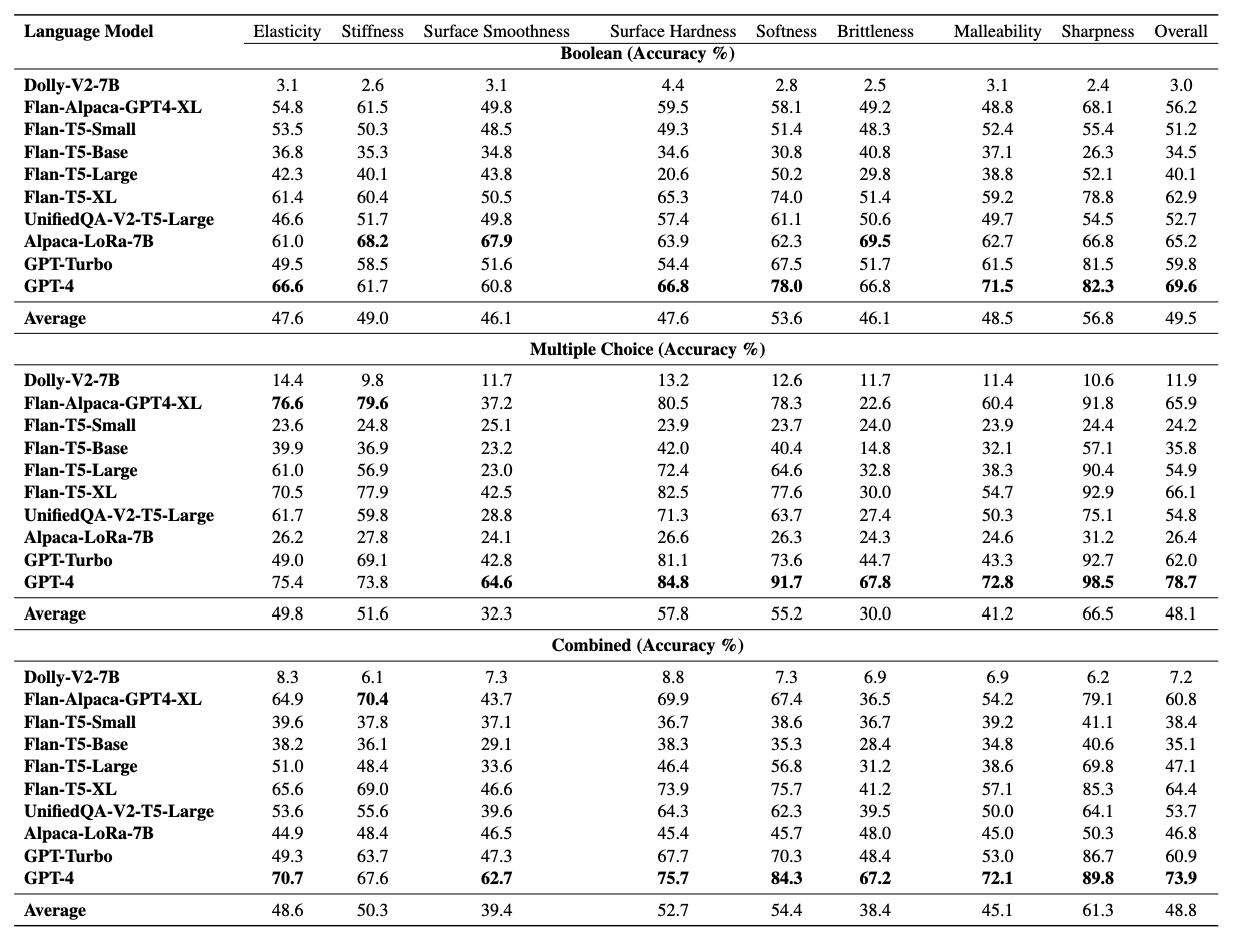
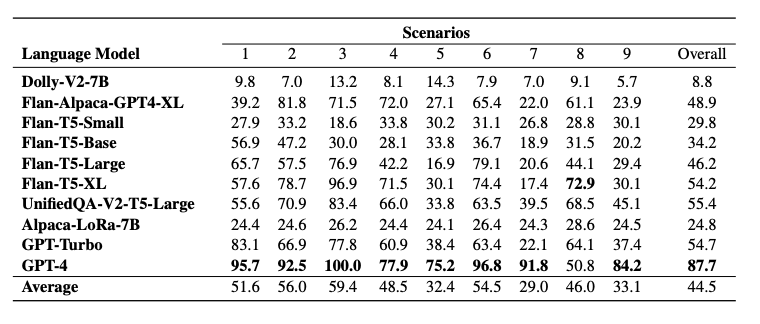
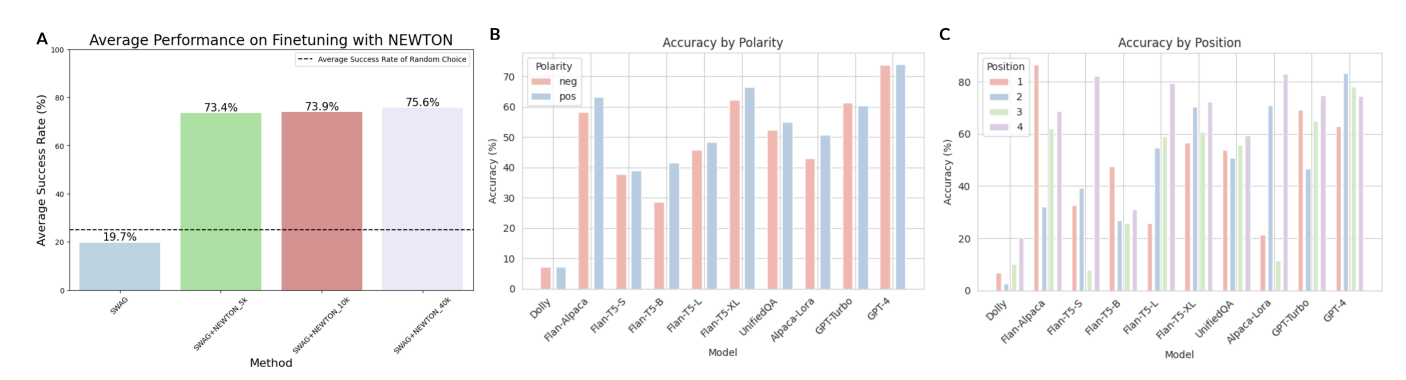
Abstract
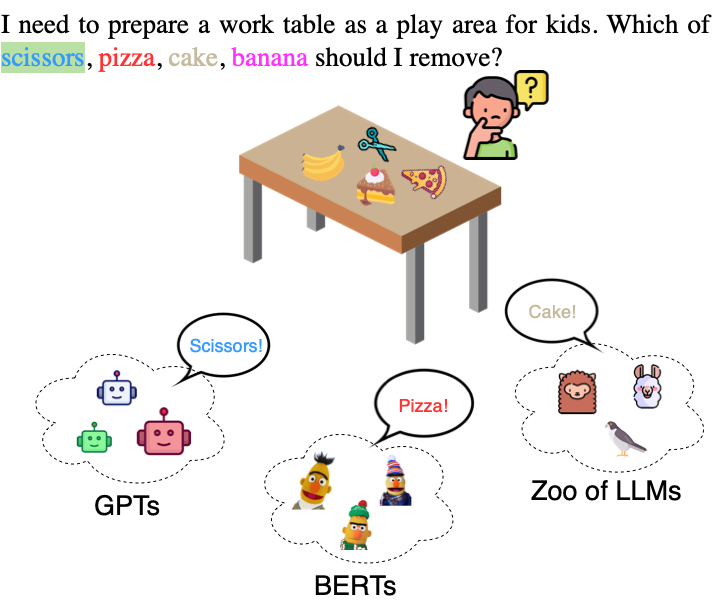
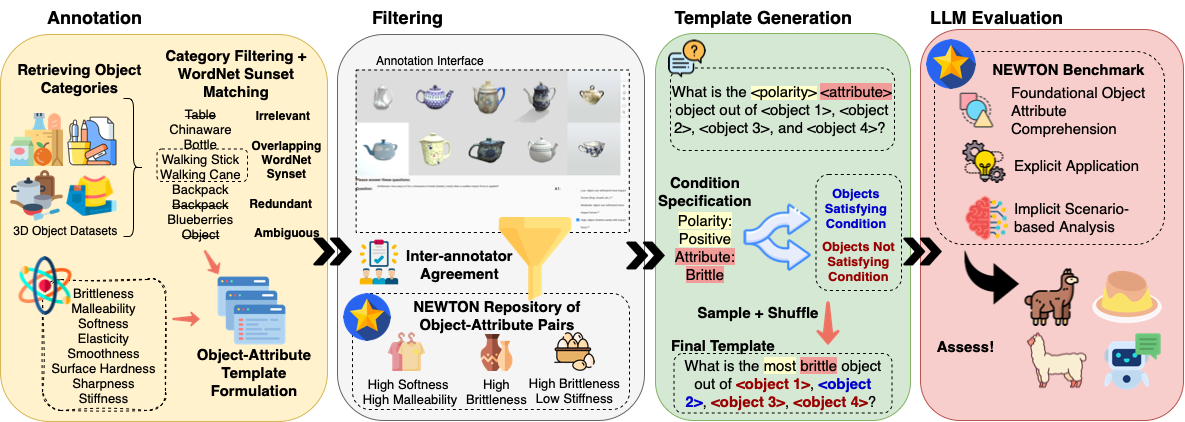
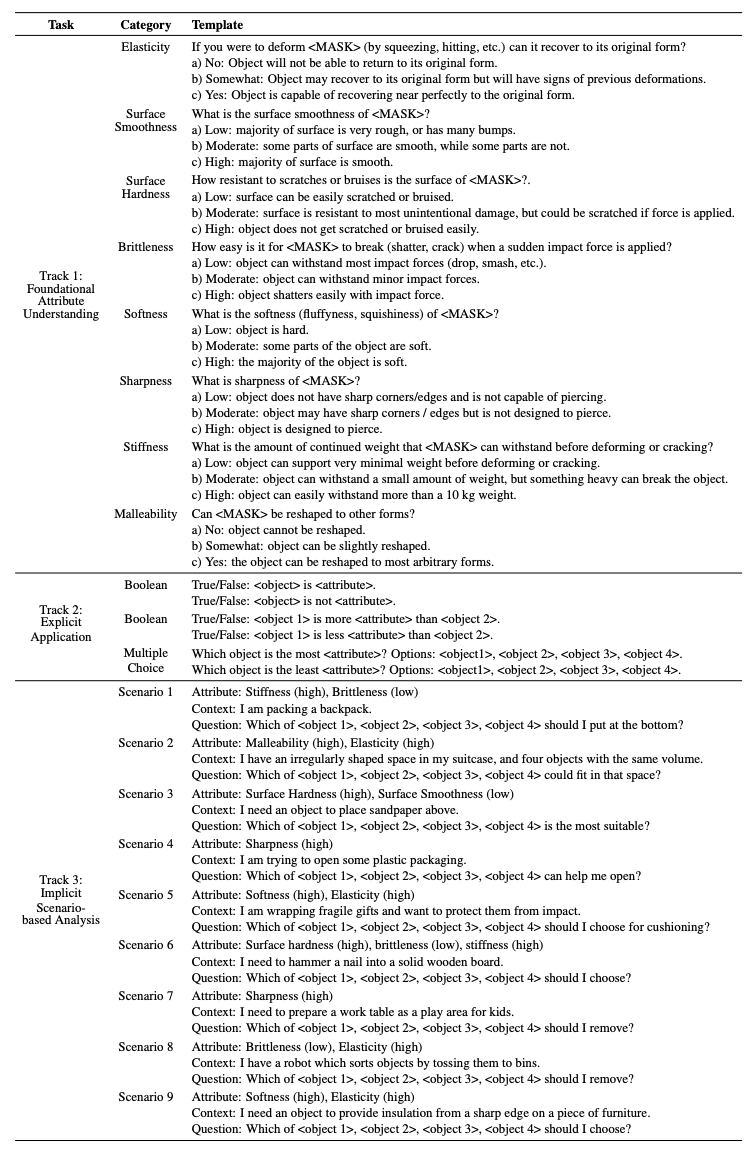
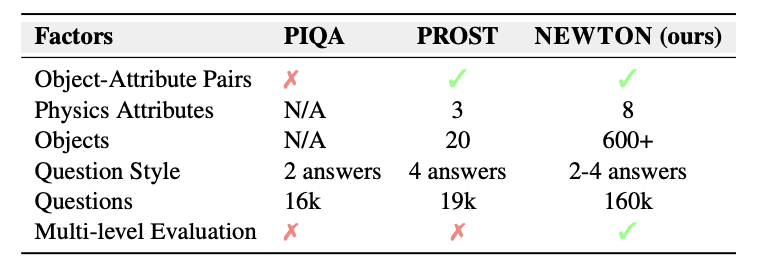
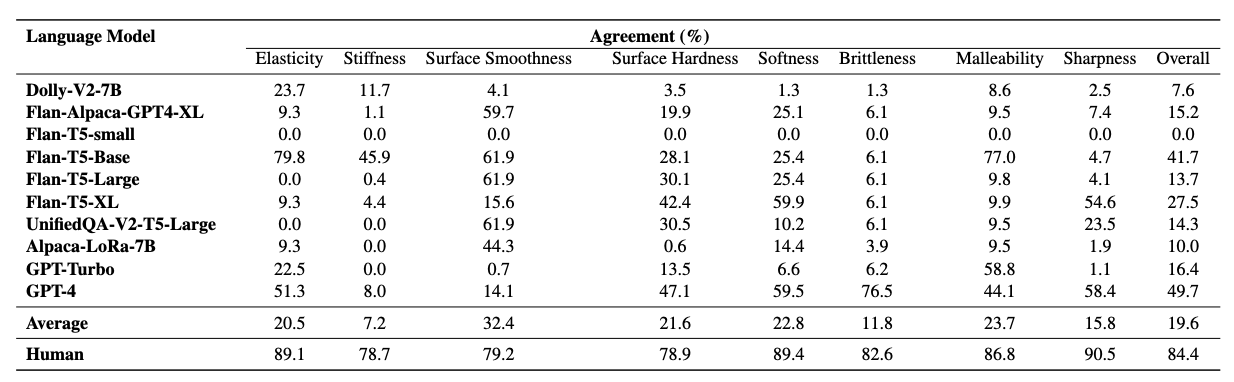
Training language models on extensive unprocessed text data has yielded impressive advancements in natural language processing (NLP), particularly in tasks such as question answering and reading comprehension. These models, through their contextualized representations, have been proven in numerous studies to encapsulate syntactic, semantic, word sense, and common-sense knowledge. However, there has been limited exploration of their physical reasoning abilities, specifically concerning the crucial attributes for comprehending everyday objects. To address this gap, we introduce NEWTON dataset, a comprehensive Repository, Pipeline, and Benchmark designed to facilitate streamlined evaluation of Large Language Models (LLMs) in the context of physical reasoning. The dataset Repository comprises a vast collection of object-attribute pairs, providing the foundation for generating infinite-scale assessment templates when combined with the NEWTON Pipeline. Leveraging this infrastructure, we construct a large-scale QA dataset to investigate the physical reasoning capabilities of several mainstream language models across foundational, explicit, and implicit reasoning tasks.
Through extensive empirical analysis, our results highlight the capabilities of LLMs for physical reasoning. Furthermore, the NEWTON platform demonstrates its potential for evaluating and enhancing language models, paving the way for their integration into physically grounded settings.